Upcoming Features
See what's coming next to the platform.
2026 Q1
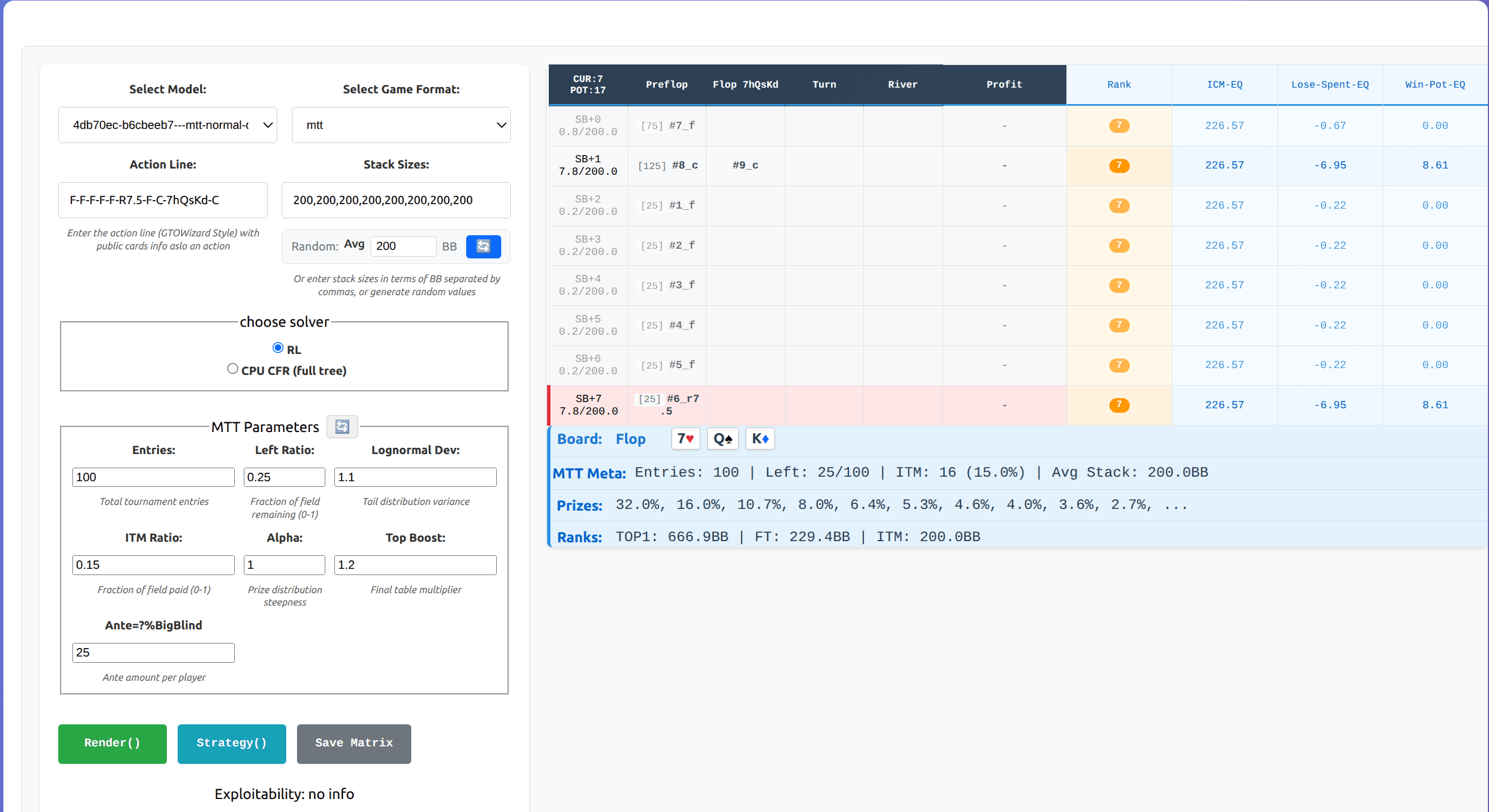
RangeViewer MTT Equity & UI Update
🚀 Highlights
Introduced comprehensive support for Multi-Table Tournament (MTT) analysis in RangeViewer. This update brings a dedicated UI for configuring tournament scenarios, a powerful backend engine for real-time ICM (Independent Chip Model) calculations, and detailed equity visualization on the poker table. Users can now analyze decisions with precise tournament context, including prize structures, field distributions, and "risk premium" metrics like Win-Pot and Lose-Spent equity.
🆕 What's New?
- MTT Parameter Configuration: Added a comprehensive input panel in the Model Selector. Users can now define:
- Entries: Total number of players.
- Left Ratio: Percentage of the field remaining.
- ITM Ratio: Percentage of places paid.
- Prize Distribution: Controls for
Alpha(steepness) andTop Boost(final table payouts). - Lognormal Dev: Variance of the chip stack distribution across the field.
- Advanced ICM Metrics: The poker table now includes dedicated columns for:
- ICM-EQ: Real-time Independent Chip Model equity in Big Blinds.
- Win-Pot-EQ: The equity gained if the player wins the current pot.
- Lose-Spent-EQ: The equity lost if the player folds or loses the pot.
- Rank: Estimated global rank based on stack size relative to the generated field.
- Tournament Status Bar: A new info row displays critical tournament context, including "Players Remaining", "ITM Places", "Average Stack", and a summary of the "Prize Structure".
- Randomization Tools: Added "Shuffle" buttons to quickly generate realistic random stack sizes (with a configurable average) and random MTT scenarios for stress-testing and exploration.
🐛 Bug Fixes
- Fixed layout issues where new table columns could break the responsive design on smaller screens.
- Addressed potential calculation errors when ICM parameters resulted in invalid prize structures.
🔧 Improvements
- Robust ICM Engine: Integrated
mtt_utilswith a "Quadrature Tail ICM" algorithm. This ensures accurate equity calculations even for large fields and complex prize structures where traditional methods might fail or be too slow. - Visual Enhancements: Added color-coded badges for key ranks (e.g., "TOP1", "FT" for Final Table, "ITM") to make high-value situations instantly recognizable.
- Performance: Cached ICM calculations per game state to ensure the UI remains responsive even with complex math running in the background.
📅 Timeline / Status (For Upcoming Features)
- Design: [Completed]
- Development: [Completed]
- Target Release: [2026-01-05]
Strategy Profile V3 & CSV Loading
🚀 Highlights
Introduced a robust CSV-based loading mechanism for strategy profiles, enabling easier management and deployment of new strategies without recompilation. Enhanced the strategy selector to support post-flop adjustments based on profile naming conventions ("wtsd").
🆕 What's New?
- CSV Strategy Loading: Strategy profiles are now loaded dynamically from
rlserv/settings/*.csvfiles, merging with existing configurations. - Post-Flop Strategy Support: Updated
human_like_strategy_profile.ccto support strategy adjustments in post-flop rounds if the target profile name starts with "wtsd". - S3 Model Downloader: Added
scripts/download_s3_model_for_local_rlserv.pyto simplify fetching models from S3 for local development. - Enhanced Debug Logging: Improved error reporting when requested game formats or profiles are missing in
StrategyProfileSelector. - New Strategy Profiles: Added initial set of CSV profiles for Preflop and Postflop strategies (v2 and v3 variants).
🐛 Bug Fixes
- None reported.
🔧 Improvements
- Configuration: Updated
server_config.jsonto enable CSV loading by default viastrategy_profile_csv. - System Initialization:
SystemInitializernow handles the merging of CSV-based profiles into the global configuration at startup.
📅 Timeline / Status (For Upcoming Features)
- Design: [Completed]
- Development: [Completed]
- Target Release: [2026-01-05]
CUDA-Accelerated Texas Hold'em Environment
🚀 Highlights
This release introduces a fully CUDA-accelerated Texas Hold'em environment, holdem_cuda, designed to significantly accelerate Reinforcement Learning (RL) training workflows. By moving the core game logic—dealing, action validation, and state transitions—to the GPU, we enable massive parallelism (e.g., 8192+ concurrent environments) and reduced data transfer overhead.
🆕 What's New?
- Vectorized Environment (
VectorHoldemEnv): A new C++ class exposed to Python that manages thousands of poker games in parallel on the GPU. - CUDA Kernels: Core logic for
deal,step, andresetis now implemented in CUDA (holdem_cuda.cu) for high-throughput execution. - MTT & ICM Support: Integrated Independent Chip Model (ICM) equity calculations (
icm_equity_with_param) to support Multi-Table Tournament (MTT) training scenarios. - Side-Pot Aware Rewards: Precise reward calculation handling split pots and side pots, processed efficiently by worker threads.
- PyTorch Integration: Direct tensor input/output support, ensuring seamless integration with PyTorch-based training loops (PPO, etc.).
🔧 Improvements
- Performance: Achieves millions of environment steps per second (throughput depends on GPU) by minimizing CPU-GPU synchronization.
- Memory Efficiency: Optimized
Statestruct layout and in-place operations to maximize GPU memory utilization. - Asynchronous Processing: Uses worker threads to handle CPU-bound tasks (like complex reward computation and logging) while the GPU continues stepping.
⚠️ Breaking Changes
- API Shift: This release introduces
VectorHoldemEnvwhich may have a different API surface compared to the previous CPU-only implementation. Users should update their training loops to handle batched tensor observations and actions. - Dependency: Requires an NVIDIA GPU and CUDA toolkit to build and run.
📅 Timeline / Status
- Development: Completed
- Testing: Benchmarked against CPU reference (
agrlsim) - Target Release: 2026-01-05
MoE Strength: 2Blinds Dedicated Models
🚀 Highlights
We are training dedicated Mixture of Experts (MoE) models specifically for 2-Blind game variants (0-ante and 0.5-ante). This effort directly addresses consistency issues reported by clients using the current "Universal" production model in these specific environments.
By moving away from a single generalist model to specialized MoE architectures, we aim to provide superior strategic depth and stability for these high-traffic game formats.
🆕 Key Improvements
- Dedicated 0-Ante Model: Optimized for pure 2-blind structures without ante pressure.
- Dedicated 0.5-Ante Model: Specialized for small-ante environments to refine stealing and defending ranges.
- MoE Architecture: Leveraging Mixture of Experts to capture subtle strategic nuances that the universal model currently averages out.
- Consistency Fix: Resolving specific "unintuitive" action lines identified in client feedback logs.
🔧 Technical Details
- Architecture: MoE with 8 experts per gate.
- Training Data: Augmented dataset focusing on 2-blind dynamics.
- Validation: Strict comparison against production logs to ensure all "consistency gaps" are closed.
📅 Status
- Data Preparation: Completed
- Training: In Progress (MoE Gates convergence looks promising)
- Target Deployment: Jan 17th, 2026
2026 Q2
All-in or Fold (AoF) Ground Truth Solver
🚀 Highlights
We are initiating the development of a "Ground Truth" solver for the All-in or Fold (AoF) game format. This initiative stems from the AceSenseTeam and aims to provide a mathematically perfect baseline for this simplified poker variant.
The goal is to produce a definitive solution (GTO) by fully solving the game tree and saving all decision points, as the simplified state space allows for complete enumeration.
🎯 Objectives
- Rule Extraction: Mirror the exact game logic and rules from the
acesense-game-corelibrary. - Jackpot Integration: The solver MUST account for the specific jackpot mechanics defined in the core library, as this significantly alters EV calculations.
- Solver Implementation:
- Explore/utilize existing solvers or implement a custom algorithm (potentially "PRF" or CFR-based).
- Ensure strict adherence to the extracted rules.
- Data Persistence: Since the game tree is relatively small, the target is to save all decision points (Lookup Table approach) rather than relying on real-time neural network inference.
🔗 Resources
- Source Repo:
bitbucket.org/aceguardian/acesense-game-core(Branch:holdem-delivery-ai-v1.0) - Key Logic: Game Rules, Jackpot Probability/Payouts.
📅 Plan
- Phase 1: Analysis of
game-corelogic and rule extraction. - Phase 2: Algorithm selection and prototype implementation.
- Phase 3: Full solution computation and verification.
- Phase 4: Integration/Migration to AGRL2 (Optional/TBD).